作为一个 Linux 老用户,有一个魔鬼永远在网卡上盘旋,那就是 iptables 。你永远不知道配置完后会发生什么奇怪的问题。而随着接力棒的传递,新一代 Linux 发行版最常见的 nftables 已经发布了有一阵子,所以系统的了解一下是有必要的。
1 、 xtables 和 nftables 的历史
Netfilter 是 Linux 内核提供的一个框架,它允许以自定义处理程序的形式实现各种与网络相关的操作。 Netfilter 为数据包过滤、网络地址转换和端口转换提供了各种功能和操作,这些功能和操作提供了引导数据包通过网络并禁止数据包到达网络中的敏感位置所需的功能。
Netfilter 代表 Linux 内核中的一组钩子,允许特定的内核模块向内核的网络堆栈注册回调函数。这些函数通常以过滤和修改规则的形式应用于流量,为遍历网络堆栈中相应钩子的每个数据包调用。
而在 Netfilter 中,曾经存在四样配置工具去操作 Netfilter 。分别是 iptables ip6tables arptables ebtables 统称 xtables
因为 ipv4 和 ipv6 分别管理的繁琐,以及这四样配置工具导致的各种问题,nftables 被做了出来,专门用来统一上述四种配置工具。其中最解决问题的 动态更新 作为主打特色,免除断线困扰。
但是因为 xtables 中的 iptables 太出名了,所以大多数只使用 iptables 的认为 nftables 只是作为 iptables 的升级替换,结果真到 nftables 发现两者的配置命令并不相通。
1.1 、 Netfifter 和 传统数通网络 的区别
用户或运维配置防火墙,就是希望流量按照自己的需求和想法,该怎么走就要怎么走。
身为一个网络工程师,在配置交换机路由器时,肯定接触过两个东西 ip access-list route-map 这两样东西伴随着各品牌数通设备,几乎无处不在。
当我们管理流量的时候,ip access-list extended 用到端口五元组 源地址 源端口 目的地址 目的端口 传输层协议 并借此匹配到一种处理方案。
当我们调配流量的时候,route-map 借由 access-list 去 match 流量,并 set 对应的信息以执行下一跳路由等多种决策。
当我们配置 NAT 地址转换 时,ip nat inside 并根据后缀命令参数决定哪些地址转换成哪些地址
到了 netfilter 这边,首先同样作为一个古董,它和数通设备的思维策略基本一致,毕竟同样作为网络管理的一部分
用 cisco 配置命令的角度去观察 netfilter 针对 tcp/ip 所调度的 xtables 的设计,你可以发现很多一样的
access-list 直接应用在端口 === xtables filter 表 input output 链
access-list 应用在 route-map === xtables mangle 表 的全体链
route-map === xtables filter 表 forward 链,以及全体 prerouting/postrouting 链
nat inside/outside === xtables nat 表
rule X === xtables 状态机顺序优先级
iptables 有两个规则方案 QUEUE 和 RETURN ,数通设备则是根本不用,access-list 只有 accept 和 drop 两大规则
这样的角度一看,这两者差不多,只是换个命令的问题。但是两方有个根本上的东西不同,就是流量类型。
数通设备 99% 的流量都是 Forward 类型,而 Netfilter 所处理的流量是含有其自身的三大种 Input Output Forward
这导致一个很繁琐的问题,如何理解 Input 和 Output 与 Forward 的区别?以及两者的共存应当如何调配?
数通设备很简单,只需要把 Input 和 Output 流量从接口上按照 Forward 流量进行处理即可,全面强化 Forward 性能。
Netfilter 设备则认为,Input 和 Output 是两种主要的流量,Forward 与他们并行,但双方尽量不互通,用以区分开。
1.2 、网络的 xtables 的坑爹攻略
xtables 长期没有什么大更新,因为有 巨量 的应用,硬性的绑死了 xtables 的各种配置方式。其中首当其冲的内容就是 xtables 只维护几张固定表,而哪张表一旦有变化,全表都要被重置。而在维护的过程中,经常体验到 xtables 配置的一条规则 越界 操作其他流量了,又因为全表刷新,根本没有机会私下测试测试。
难以升级,难以改变,难以操作,维护人员只能做个好看的工具 动态防火墙管理工具 简化配置步骤。但同样的 init 和 systemd 在 2014 年在 Debian 社区公投中,init 正式被 Systemd 替代。而 xtables 就算到了 2020 年,即使大多数人都知道 nftables 被检验了五年稳定性有目共睹,xtables 依然还在发行版中毅力不倒。
或许说,当 Linux 的网络遇到问题,你总能在 xtables 找到答案,或者找到解决办法,因为在 xtables 撞过头破血流的人比比皆是。而你想搜索一些 nftables 解决方案,Google 的中文区内容基本都会让你 “先去 iptables 试试”,或者 “先看点 iptables 是怎么回事” 。这种倒退的方式实在令人咂舌。
我永远 厌恶 :xtables 不管多复杂能用就这样用着甚至教别人也按照这个方式来 的行为习惯
我永远 厌恶 :所有 卸载 动态防火墙管理工具 然后教新人一条条敲 iptables -A INPUT 的犯蠢行为,有一个骂一个。
1.2 、如何弃用 iptables
因为耦合度太高,你基本不可能卸载 xtables 而还用着防火墙的基础功能,因为 Netfilter 的钩子一直都在。
但是用脚投票,我们可以废掉与它的交互,并且在未来有真正能替换的东西时彻底干掉。
重点抵制 Docker-ce 依然写 iptables 自动策略,社区里虽然有讨论但并不是关注方向。
(Podman 可以替代 Docker 而且是去商业实现)
sudo apt install nftables firewalld sed -i "s/FirewallBackend=iptables/FirewallBackend=nftables/g"
在 Ubuntu 20 之后的版本,安装 firewalld 默认就是 nftables 。但实际上,nftables 依然调用着 Netfilter,但 iptables 不再管控规则列表了(架空)
输入后,firewalld 会自动创建 firewalld 表 和 规则链
但是,卸载后你需要明白,到底哪些应用写死了代码只能用 xftables ,因为可能会崩。
1.3 、动态防火墙管理工具
如果一个程序足够轻松易懂,为什么还会有大量的管理工具呢?
UFW & Firewalld 两款动态防火墙管理工具,在两个 Linux 常用发行版 Ubuntu / Redhat 中被应用。
其中 ufw 因为被吐槽太多,以至于被 Ubuntu 直接在安装后禁用了。毕竟折腾 Ubuntu 的人都乐意搞点操作。同样因为 ufw 只是给 iptables 开发,而 ufw 反而限制了 iptables 更多特性的使用,导致 iptables 的问题在 ufw 会同样出现。问题没变少,反而变多了,自然用的人越来越少。而 Firewalld 则是因 Redhat 系的维护优先,从安装到云服务都是开启的,长期维护导致有足够多的磨练,质量相对较高。
但是还是因为耦合性的问题,当你使用 firewall-cmd --add-rich-rule= 添加规则时,大概率会因为其他软件写死的规则和 firewalld 注入的规则撞车,导致 xtables 表炸裂。以至于 Redhat 都不推荐这样注入使用。
nftables 的 模块化 理念和 firewalld 的 Zone 理念相对近似,并且 firewalld 在 0.6 版本后就开始联合 nftables 使用了。
(谁会想重蹈 ufw 的坑呢?)
2 、从零开始的 nftables
现在,我们忘记世界上还有一个 xtables 命令行工具 的东西,世界线只有 nftables ,以及 Netfifter 。
忘记那些乱七八糟的坑死人对比教程,nftables 把 xtables 兼容层 扔了是个独立工具,不是个 xtables 创意工坊的 MOD 和 DLC(Nftables 许多人写的文章里缺少名词解释,靠 xtables 衬托对比,新概念就那么难理解么)
系统版本 Ubuntu 20.04.1 + nftables v0.9.3 (Topsy) + firewall-cmd v0.8.2
2.1 、 nftables 基本概念
nftables 是 Netfilter 的一部分。
Netfilter 是 Linux 内核的一个子系统,提供网络 数据包/数据报文/帧 的过滤和分类。
nftables 由三个主要组件组成:内核实现、 libnl&netlink 通信和 nftables 用户空间前端。
内核实现:提供了一个 netlink 配置接口以及运行时规则集的评估
Netlink:是基于 socket 的用户空间进程和内核态进程通信的方式,调用内核为用户态程序提供的很多接口 [ 链接 ]
libnl:封装了 netlink socket 底层操作,包含与内核通信的基本函数,提供了一系列高级 API,简化了 netlink 编程 [ 链接 ]
nftables 用户空间: 引导用户通过 nft 命令对 nftables 进行管理。
通过用户空间实用工具 nft 配置,可以管理 IPV4 、 IPV6 、 ARP 、数据链路层 等 多种流量与配置。 [ 链接 ]
2.1.1 、 Nftables 处理顺序
可以看到对于一个流量,从逻辑结构上 nftables 是采用非线性处理方式分配流量,而并非完全的状态机。
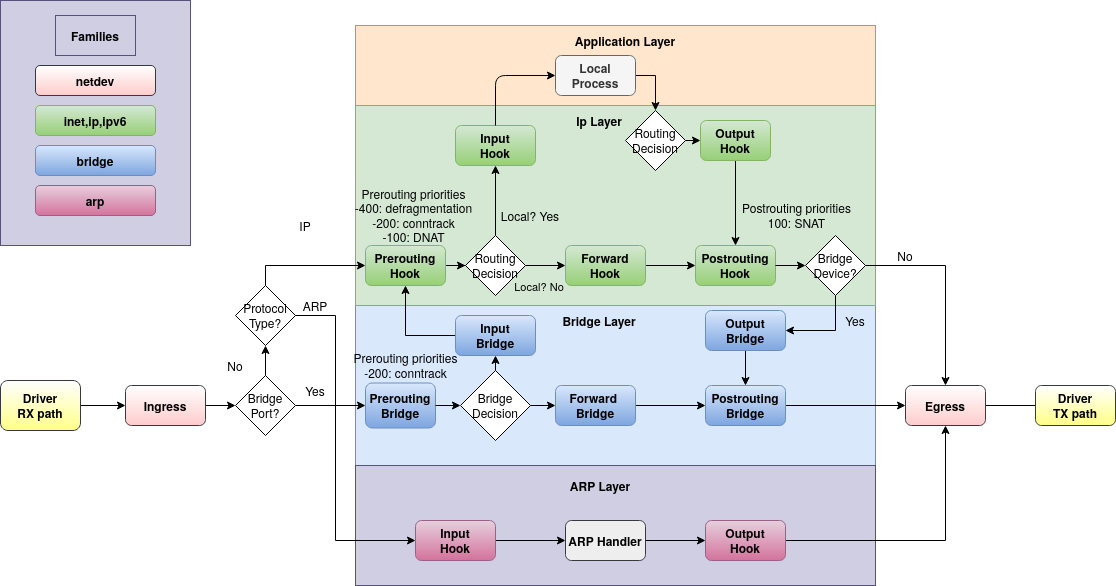
看着可能有点眼熟,不是么
Nftables 采用 Hook 钩子 设计,通过 基础链钩子 Basic Chain + Hook 抓取流量并用 规则 Rule 处理。
当 Hook 钩子钩中了同一批流量,则按照 基础链优先级 Basic Chain + priority 进行顺次执行,除非有规则 Drop 了。
PS:一定要提醒一个问题,ARP 发送请求是一个 ARP Layer 的广播,但是回复请求会被认为是 IP / IPV6 报文。 [ 链接 ]
而对于曾经了解老版本 Linux Kernel 网络状态机的用户,对下面这张图相对比较熟悉 (RouterOS) (近似 xftables 逻辑)
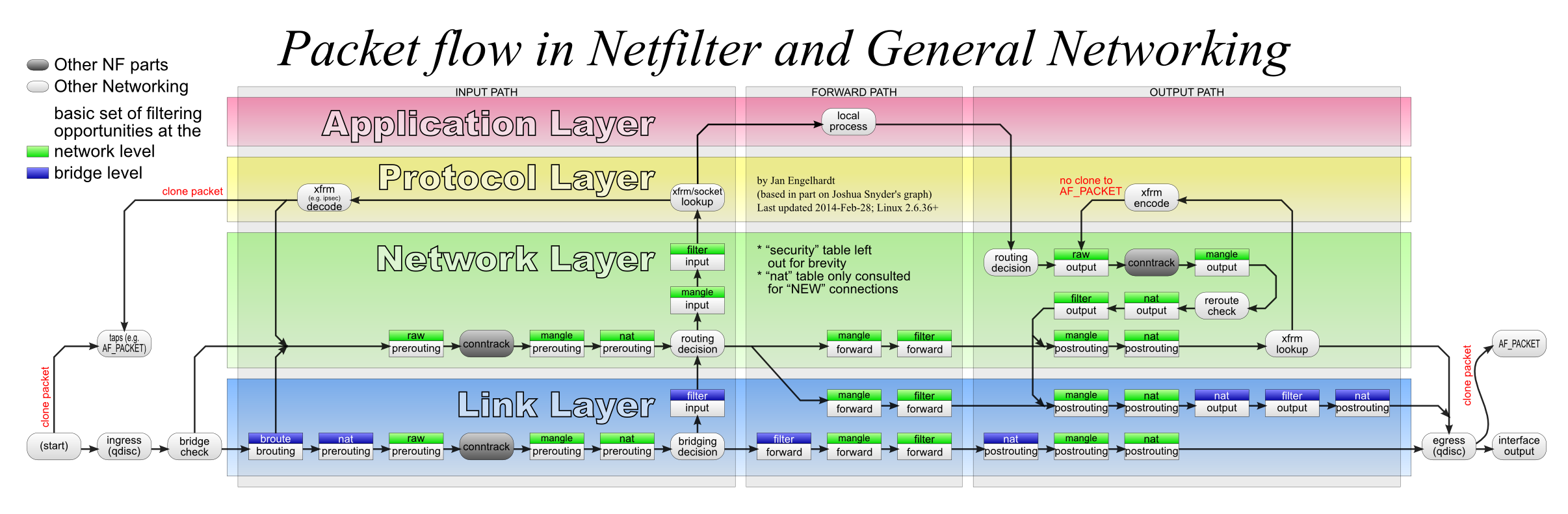
四表 RAW / MANGLE / NAT / FILTER
五链 PREROUTING / INPUT / FORWARD / OUTPUT / POSTROUTING
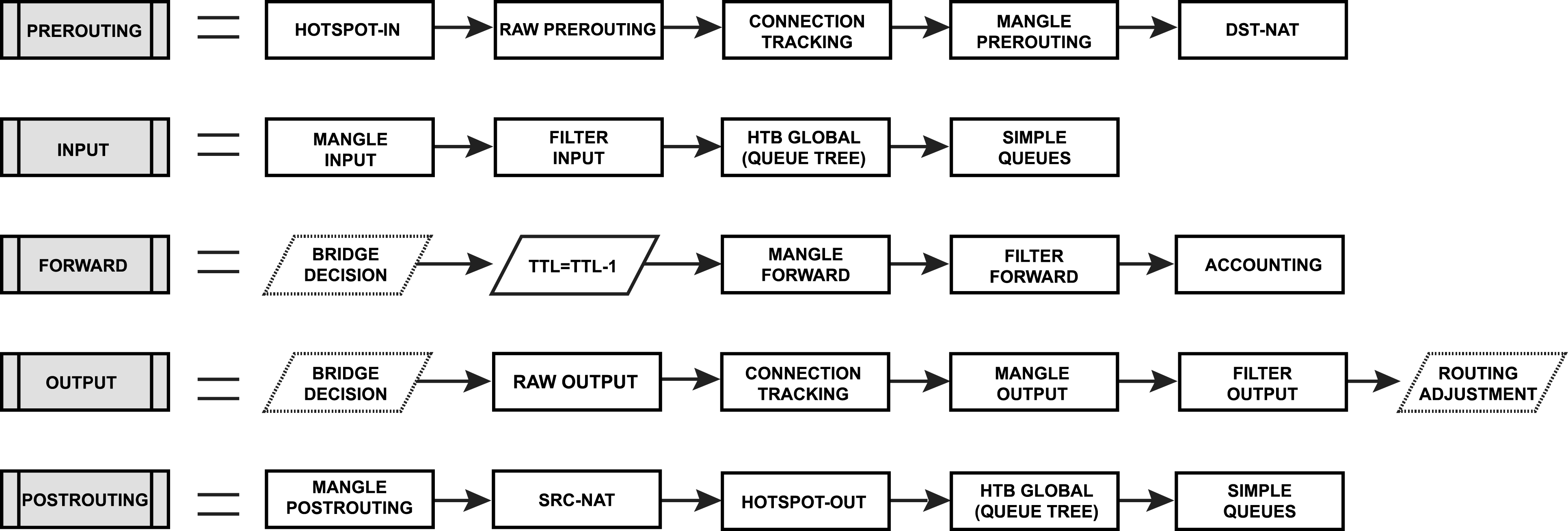
Hotspot - 允许捕获流量,否则将被连接跟踪丢弃 - 这样即使网络设置是不完整或有问题,我们的 Hotspot 功能仍然能够提供连接;
RAW Prerouting - RAW 表的 Prerouting 链;
Connection tracking - 数据包通过连接跟踪进行处理;
Mangle Prerouting - Mangle 表的 Prerouting 链;
Mangle Input - Mangle 表的 Input 链;
Filter Input - Filter 表的 Input 链;
HTB Global - 网络队列树;
Simple Queues - 简单队列即数据包先进先出 (FIFO),数据包处理优先级使用;
TTL - 路由报文的生存时间 (Time To Live, TTL) 减少 1 的准确位置,如果 TTL 为 0,报文将被丢弃;
Mangle Forward - Mangle 的 Forward 链;
Filter Forward - Filter 的 Forward 链;
Accounting - 认证、授权和会计特征处理;
RAW Output - RAW 表的 Output 链;
Mangle Output - Mangle 表的 Output 链;
Filter Output - Filter 表的 Output 链;
Routing Adjustment - 这是一个变通方法,允许在 mangle 链输出 (路由标记) 中设置策略路由;
Mangle Postrouting - Mangle 表的 Postrouting 链;
Src Nat - NAT 表的 src 链;
Dst Nat - NAT 表的 dst 链;
Hotspot-out - 撤销由 hotspot-in 对于回复数据包的操作;
2.1.2 、 Nftables 表 链 规则
我们之前提出了 四表五链 的概念,但是在 nftables 中则不适用该概念,请勿带入(因为真的很像)。
常用命令 Nftables 查看所有规则列表
# 查看所有规则 nft list ruleset # 查看所有规则,同时显示添加顺序(handle 标记 搭配 position 使用) nft list ruleset -a # 使用交互方式输入规则(显示添加顺序) nft -i -a
额外注意,Nftables 经常使用 {} - 符号,需要 单引号 限制命令信息避免被 Shell 转义特殊字符(或者使用 nft -i 交互)
nft 'add rule ... { ... }'
2.1.2.1 、 Nftables 表
Nftables 表 是 Nftables 的一种容器,存放 chain 链
Nftables 表 无法修改名称,仅存在 flag 可能会有更新。
Nftables 表 需要定义 数据包 的 family 地址簇 类型,用以限定引用范围
Nftables 表 对 规则顺序 没有影响,仅限定了 规则 的使用区域与地址簇类别
Nftables 表 可以使用 标志位 flag 暂时禁用所有规则,且仅有 dormant 唯一标志 {flags dormant;}
Nftables 表 所使用的 地址簇family 一共有六大类
主四类为 ip / ip6 / bridge / arp,分别对应 IPV4 / IPV6 / L2 / ARP 专项
第五类为 ip&ip6 双栈使用的 inet , 不能搭配 nat 类型链,只能搭配 filter 类型链,且网络层流量会自动匹配对应协议栈规则|
第六类为 netdev ,优先级顺序最高,通常用于代码开发和排障测试使用。
Nftables 表的配置需要参考如下
可选项 [<family>] 的默认值是 ip,在不填写的时候会自动填入
可选项 [<flags>] 的默认值是 无,在不填写的时候为激活,填写 {flags dormant;} 的时候暂时禁用
nft add|create table [<family>] <table_name> [{ flags flags ; }]
nft list|delete|flush table [<family>] <table_name>
# 列出所有表
nft list tables
# 增加一个表/更新一个表含有指定 flags
nft 'add table inet demo_table {flags dormant;}'
# 列出指定表
nft iist table inet demo_table
# 清空指定表
nft flush table inet demo_table
# 删除指定表
nft delete table inet demo_table
2.1.2.2 、 Nftables 链
Nftables 链 是 Nftables 的一种容器,存放 rule 规则
Nftables 链 无法更新,只能增加、删除、更名
Nftables 链 内部规则按顺序从上到下执行,规则添加顺序可查看到为 #handle
Nftables 链 主要分为 正则链 和 基本链 ,没有自动生成的链,都需要手动创建
基础链:管理流经网络协议栈(TCP/IP)的数据包,必须指定钩子/类型/优先级
正则链:支持正则管理方式,主要以调度其他链和跳转为主。
Nftables 链 需要指定 类型 type 配置 流量应当以何种方式被控制(基础链强制)
Nftables 链 需要调用 钩子 hook 抓取网络数据包 才会对数据进行处理(基础链强制)
Nftables 链 需要调用 优先级 priority 管理链的优先级顺序(基础链强制)
(近似 route-map 需要 ip access-list 匹配 accept 抓取流量)
Nftables 基础链 类型 type 分为 filter / route / nat
filter:过滤数据包
route:对数据包进行重路由
nat:对 数据流 进行 网络地址转换(数据流仅第一个包会因为钩子进入本链,之后即使有钩子也会绕过)
Nftables 基础链 钩子 hook 有六种主要钩子,通过钩子进而抓取指定区域的流量
分别为 INGRESS / PREROUTING / INPUT / FORWARD / OUTPUT / POSTROUTING
(INGRESS/EGRESS 从 Kernel 4.2 后加入 NetDev 地址簇,Kernel 5.10 后加入 inet 地址簇)
INGRESS 钩子:这条钩子捕获 网卡驱动 向 内核网络接口 传递的数据包。
PREROUTING 钩子:在这条钩子捕获 刚刚进入内核网络接口的数据包。
INPUT 钩子:在这条钩子捕获 打算进入本机的本地进程之前的数据包。
OUTPUT 钩子:在这条钩子捕获 打算离开本机的本地进程产出的数据包。
FORWARD 钩子:在这条钩子捕获 那些通过并不进入主机的所有数据包。
POSTROUTING 钩子:在这条钩子捕获 准备离开内核网络接口的数据包。
IP / IP6 / INET / Bridge 表 family 地址簇 可以使用 PREROUTING / INPUT / FORWARD / OUTPUT / POSTROUTING 钩子类型
ARP 地址簇表 可以使用 Input 和 Output 钩子类型
NetDev 地址簇表 可以使用 INGRESS 钩子类型
Nftables 基础链 优先级 priority 通过 顺序排列 进而 按顺序执行不同 钩子 hook,优先级小数值优先
当重复的表和重复的链出现时,仅依靠 优先级顺序 决定优先顺序调度(
可使用 mangle -5 代表 -155 ,但限定在参考值的 ±10 以内。
用户设定 优先级 可以超越 基础链 的 内部设定优先级 ,有以下内部设定优先级
特殊 1:当存在两个拥有 相同钩子 但 钩子优先级不同 的 A/B 基础链 (A<B),会先执行 A 链 然后 执行 B 链
特殊 2:但当上方情况为 A 链 执行 Drop 时,此时数据包 Drop 行为会立即生效,并终止继续执行
| Name | Value | Families | Hooks |
| raw | -300 | ip, ip6, inet | all |
| mangle | -150 | ip, ip6, inet | all |
| dstnat | -100 | ip, ip6, inet | prerouting |
| filter | 0 | ip, ip6, inet, arp, netdev | all |
| security | 50 | ip, ip6, inet | all |
| srcnat | 100 | ip, ip6, inet | postrouting |
| dstnat | -300 | bridge | prerouting |
| filter | -200 | bridge | all |
| out | 100 | bridge | output |
| srcnat | 300 | bridge | postrouting |
Nftables 基础链 通过 选择策略 policy 决定经过所有规则后的数据包流向,分别为 Accept(默认) 和 Drop
选择 Accept 则通过匹配并继续执行 Nftables 所配置的 其他链
选择 Drop 则放弃并终止继续执行
Nftables 链的配置需要参考如下
可选项 [<family>] 的默认值是 ip
可选项 [<policy>] 的默认值是 accept
可选项 [device] 未知使用场景,待检查
nft add|create chain [<family>] <table_name> <chain_name> { type <type> hook <hook> device <device> priority <value> ; [policy <policy> ;] }
nft list|delete|flush chain [<family>] <table_name> <chain_name>
nft rename chain [<family>] <table_name> <chain_name> <chain_new_name>
# 列出所有链
nft list chains -a
# 增加一个链,两者命令效果一致(无法更新链)
nft 'add chain inet demo_table demo_chains_input { type filter hook input priority 3 ; }'
nft 'add chain inet demo_table demo_chains_input { type filter hook input priority filter + 3; policy accept; }'
# 查看一个链
nft list chain inet demo_table demo_chains_input
# 更名一个链
nft rename chain inet demo_table demo_chains_input demo_chains_input_nick
nft rename chain inet demo_table demo_chains_input_nick demo_chains_input
# 清空一个链
nft flush chain inet demo_table demo_chains_input
# 删除一个链
nft delete chain inet demo_table demo_chains_input
2.1.2.3 、 Nftables 规则
Nftables 规则 是 Nftables 的一种执行策略,只针对 chain 链 捕获的流量处理
Nftables 规则 无法更名,只能增加、插入、替换、删除。无法列出,只能通过列出链查看。
Nftables 规则 详细参数部分 [ 链接 ]
Nftables 规则 关于 Connection_Tracking 连接状态追踪 相关 [ 链接 ]
Nftables 规则 声明 Statements 的使用
accept:接受数据包并停止剩余规则评估。
drop:丢弃数据包并停止剩余规则评估。
queue:将数据包排队到用户空间并停止剩余规则评估。
continue:使用下一个规则并继续规则集评估。
return:从当前链返回并继续上一个链的下一条规则。在基链中它相当于接受
jump <chain> :跳转到新链,开始执行新链的第一条规则。发出 return 语句后,它将继续执行原链下一个规则
goto <chain>:类似于跳转,但执行完毕新链之后,将直接进行新链最终判定而不是包含 goto 语句的链上继续
Nftables 规则的配置需要参考
可选项 [handle] 代表指定规则位置,参考 list 时的 handle 值决定
可选项 [comment] 未知使用场景,待检查
Add 将 规则 插在 原规则列表 下面,Insert 将 规则 插在 原规则列表 上面
nft add|insert rule [<family>] <table_name> <chain_name> [handle <handle>] statement ... [comment comment] nft replace rule [<family>] <table_name> <chain_name> handle <handle> statement ... [comment comment] nft delete rule [<family>] <table_name> <chain_name> handle <handle>
# 添加规则,为了方便查看数值一共添加六条(第三条首行插入,第五条指定行插入,第七条强制计数)
nft add rule inet demo_table demo_chains_input ip daddr 127.0.0.11 accept
nft add rule inet demo_table demo_chains_input ip daddr 127.0.0.12 drop
nft insert rule inet demo_table demo_chains_input ip daddr 127.0.0.13 queue
nft add rule inet demo_table demo_chains_input ip daddr 127.0.0.14 continue
nft add rule inet demo_table demo_chains_input handle 3 ip daddr 127.0.0.15 return
nft insert rule inet demo_table demo_chains_input ip daddr 127.0.0.16 counter
nft insert rule inet demo_table demo_chains_input ip daddr 127.0.0.17 counter packets 10 bytes 800
# 最终效果
table inet demo_table { # handle 301
chain demo_chains_input { # handle 1
type filter hook input priority 3; policy accept;
ip daddr 127.0.0.17 counter packets 10 bytes 800 # handle 8
ip daddr 127.0.0.16 counter # handle 7
ip daddr 127.0.0.13 queue num 0 # handle 4
ip daddr 127.0.0.11 accept # handle 2
ip daddr 127.0.0.12 drop # handle 3
ip daddr 127.0.0.15 return # handle 6
ip daddr 127.0.0.14 continue # handle 5
}
}
2.2 、 Nftables 实际操作
有关于 Linux kernel 如何处理 网络流量 可以参考 Packet Flow in RouterOS [ 链接 ]
其实关于处理网络流量,Linux Kernel 其实参考的就是 Netfilter 。但因为 深度优化 等原因,在细节上可能有所不同。
2.2.1 、最简单的防火墙
table inet firewall {
chain incoming {
type filter hook input priority filter; policy drop;
# established/related connections
ct state {established,related} accept
# loopback interface
iifname lo accept
# icmp
icmp type echo-request accept
icmpv6 type echo-request,nd-neighbor-solicit accept
# open tcp ports: sshd (22), httpd (80)
tcp dport {ssh, http} accept
# invalid connections
ct state { invalid } drop
}
}
最简单的防火墙,当然是按照简单的来配
首先声明 Nftables 表链
表:名称 firewall,地址簇 inet 双栈
链:名称 incoming ,类型 filter 数据过滤,钩子位置 input 输入,优先级 0,链匹配完毕后丢弃报文
然后我们在内部放行数据流量
1 、允许所有会话状态为 已建立连接 分支链接 两种状态的会话流量为通过
2 、允许 lo 接口的流量为通过
3 、允许 icmp 报文 关于 ping 回复的流量为通过
4 、允许 tcp 协议的 ssh 22 端口 和 http 80 端口 流量为通过(不关注会话状态,无效流量也放行)
5 、将所有未追踪流量丢弃
按照这个逻辑,我们配置完毕后,防火墙会自动处理流量,禁止其他端口流量进入本机,但不限制出方向
那开始配置吧
nft add table inet firewall
nft add chain inet firewall incoming {type filter hook input priority filter; policy drop;}
敲完你会发现,网络断了!这就是因为其中 policy 选择了 drop 导致的问题,这个规则匹配后,把其他流量都禁止了,所以导致业务中断。而我们正常的配置顺序应该是 先 休眠 后 激活,先 accept 后 drop
nft add table inet firewall '{flags dormant;}'
nft add chain inet firewall incoming '{type filter hook input priority filter; policy accept;}'
nft add rule inet firewall incoming ct state '{established,related}' accept
nft add rule inet firewall incoming 'iifname lo accept comment "Permit Localhost"'
nft add rule inet firewall incoming icmp type echo-request accept
nft add rule inet firewall incoming icmpv6 type '{echo-request,nd-neighbor-solicit}' accept
nft add rule inet firewall incoming tcp dport '{ssh, http}' accept
做完操作后,你可以输入命令切换 链 默认的 选择策略
nft add chain inet firewall incoming '{ policy drop;}'
然后激活该表的规则
nft add table inet firewall
操作完后可以查看到状态如图
table inet firewall { # handle 10
chain incoming { # handle 1
type filter hook input priority filter; policy accept;
ct state { established, related } accept # handle 2
iifname "lo" accept comment "Permit Localhost" # handle 3
icmp type echo-request accept # handle 4
icmpv6 type { echo-request, nd-neighbor-solicit } accept # handle 5
tcp dport { 22, 80 } accept # handle 6
ct state { invalid } drop # handle 7
}
}
而标准网络结构中,防火墙应当回复一个报文,告诉对方被拒绝了。我们此时需要额外补充一个内容在结尾 [ 链接 ]
使用 icmpx 则是因为 icmpx 同时支持 icmpv4 和 icmpv6 的 admin-prohibited 和 port-unreachable
nft add rule inet firewall incoming reject with icmpx type admin-prohibited
2.2.2 、端口五元组
我们经常需要过滤指定流量,但如何区分呢,端口五元组是一个很有效的方案
而在 nftables 中,关于端口五元组的方式如下
# 源地址 ip saddr 0.0.0.0/0 # 目的地址 ip daddr 0.0.0.0/0 # tcp 源端口 tcp sport 5000-5010 # udp 目的端口 udp dport 5000-5010 # 传输层协议 ip protocol tcp
但是这些不够用,我们还需要更多配置选项,例如
# 入向物理接口
iifname
# 出向物理端口
oifname
#连接会话状态
ct state { new, established, related, untracked }
# tcp 标志位
tcp flags { fin, syn, rst, psh, ack, urg, ecn, cwr}
# ICMP 类型
icmp type {echo-reply, destination-unreachable, source-quench, redirect, echo-request, time-exceeded, parameter-problem, timestamp-request, timestamp-reply, info-request, info-reply, address-mask-request, address-mask-reply, router-advertisement, router-solicitation}
icmpv6 type {destination-unreachable, packet-too-big, time-exceeded, echo-request, echo-reply, mld-listener-query, mld-listener-report, mld-listener-reduction, nd-router-solicit, nd-router-advert, nd-neighbor-solicit, nd-neighbor-advert, nd-redirect, parameter-problem, router-renumbering}
# 源 MAC 地址
ether saddr 00:0f:54:0c:11:04
# 二层网络类型
ether type vlan
# vlan id
vlan id 4094
2.2.3 、跨区域流量的管理
当我们将流量按照 Nftables 区域分好时,在多区域会发现一个问题,例如 public 的流量,尝试从 trusted 出去,结果流量被防火墙阻止。此时会存在两种情况
1 、用户根据 interface 划分流量,由于 interface 只能归属一个区域,所以目的端口是该区域内流量放行,目的端口是该区域外则按照 AllowZoneDrifting 执行,但新版本无此参数,则流量阻断
2 、用户根据 source 划分流量,由于 source 可以划分到多个区域,在 Firewalld v1.2 版本前优先于按端口划分,所以顺序匹配,全都走 source 匹配到同一区域进而放行,而匹配失败的还是会最终阻断。
而这个问题在旧版本不存在,因为为了保证和 iptables 的兼容性,所有设置目的端口是该区域外的,会遵循 catch-all 原则再匹配一次,此时如成功匹配到第二区域的流量,进而放行。
旧版本例如 v0.8.2 /etc/firewalld/firewalld.conf 中,存在相关字段。 [ 链接 ]
# AllowZoneDrifting # Older versions of firewalld had undocumented behavior known as "zone # drifting". This allowed packets to ingress multiple zones - this is a # violation of zone based firewalls. However, some users rely on this behavior # to have a "catch-all" zone, e.g. the default zone. You can enable this if you # desire such behavior. It's disabled by default for security reasons. # Note: If "yes" packets will only drift from source based zones to interface # based zones (including the default zone). Packets never drift from interface # based zones to other interfaces based zones (including the default zone). # Possible values; "yes", "no". Defaults to "no". AllowZoneDrifting=yes
而新版本 v1.0.0 中,出于防火墙定义的考虑,相同区域默认允许转发,不同区域默认禁止流通,明确停用此参数。 [ 链接 ]
同时由于 --set-target 参数暂时失效,用户无法修改默认区域的结束标签 [ 链接 ]
--permanent [--zone=zone] --set-target=target
Set the target of a permanent zone. target is one of: default,
ACCEPT, DROP, REJECT
default is similar to REJECT, but has special meaning in the
following scenarios:
1. ICMP explicitly allowed
At the end of the zone's ruleset ICMP packets are explicitly
allowed.
2. forwarded packets follow the target of the egress zone
In the case of forwarded packets, if the ingress zone uses
default then whether or not the packet will be allowed is
determined by the egress zone.
For a forwarded packet that ingresses zoneA and egresses zoneB:
· if zoneA's target is ACCEPT, DROP, or REJECT then the
packet is accepted, dropped, or rejected respectively.
· if zoneA's target is default, then the packet is accepted,
dropped, or rejected based on zoneB's target. If zoneB's
target is also default, then the packet will be rejected by
firewalld's catchall reject.
3. Zone drifting from source-based zone to interface-based zone
This only applies if AllowZoneDrifting is enabled. See
firewalld.conf(5).
If a packet ingresses a source-based zone with a target of
default, it may still enter an interface-based zone (including
the default zone).
所以需要用户额外进行配置,手动添加一个表让区域间转发可行。如下所示,手动添加一个许可的区域转发,从 public 到 trusted 区域。
# firewall-cmd --permanent --new-policy allowForward # firewall-cmd --permanent --policy allowForward --set-target ACCEPT # firewall-cmd --permanent --policy allowForward --add-ingress-zone public # firewall-cmd --permanent --policy allowForward --add-egress-zone trusted # firewall-cmd --reload
